專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2022-04-29 10:30:34 來源:動力節點 瀏覽1930次
動力節點小編來給大家講一下Java解析文件亂碼問題。
普通的文件是指我們平時用記事本可以看到內容的文件,例如.txt結尾的文件,這里為了測試,小編準備了了兩個編碼的文件,test.txt和test2.txt,test.txt是通過window創建的文件編碼是 GBK,test2.txt是在編輯器里創建的,編輯器的編碼是 UTF-8;
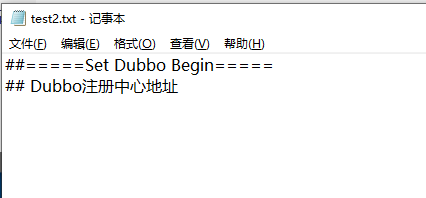
文件內容如下:
test.txt

test2.txt
方式一 :字節流讀取字節轉化為字符串顯示
//通過FileInputStream讀取字節
String path1 = "C:\\Users\\yanzhichao\\Desktop\\test.txt";
String path2 = "C:\\Users\\yanzhichao\\Desktop\\test2.txt";
InputStream inputStream1 = null;
InputStream inputStream2 = null;
try{
inputStream1 = new FileInputStream(path1);
byte[] bytes1 = T.IOUtils.toByteArray(inputStream1);
System.out.println("****************************讀取test1.txt文件 start *****************************");
System.out.println("使用默認編碼-----------------------------");
System.out.println(new String(bytes1));
System.out.println("使用UTF-8編碼-----------------------------");
System.out.println(new String(bytes1,"UTF-8"));
System.out.println("使用GBK編碼-----------------------------");
System.out.println(new String(bytes1,"GBK"));
System.out.println("使用GB2312編碼-----------------------------");
System.out.println(new String(bytes1,"GB2312"));
System.out.println("使用ISO-8859-1編碼-----------------------------");
System.out.println(new String(bytes1,"ISO-8859-1"));
System.out.println("****************************讀取test1.txt文件 end *****************************");
inputStream2 = new FileInputStream(path2);
byte[] bytes2 = T.IOUtils.toByteArray(inputStream2);
System.out.println("****************************讀取test2.txt文件 start *****************************");
System.out.println("使用默認編碼-----------------------------");
System.out.println(new String(bytes2));
System.out.println("使用UTF-8編碼-----------------------------");
System.out.println(new String(bytes2,"UTF-8"));
System.out.println("使用GBK編碼-----------------------------");
System.out.println(new String(bytes2,"GBK"));
System.out.println("使用GB2312編碼-----------------------------");
System.out.println(new String(bytes2,"GB2312"));
System.out.println("使用ISO-8859-1編碼-----------------------------");
System.out.println(new String(bytes2,"ISO-8859-1"));
System.out.println("****************************讀取test2.txt文件 end *****************************");
} catch (Exception e) {
e.printStackTrace();
} finally {
if(inputStream1 != null) {
try {
inputStream1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
代碼中T.IOUtils.toByteArray是封裝的工具類,其實里面使用的就是apache的IOUtils,這里不進行累述。
代碼讀取了兩個文件,執行結果如下:
****************************讀取test1.txt文件 start *****************************
使用默認編碼-----------------------------
111????
使用UTF-8編碼-----------------------------
111????
使用GBK編碼-----------------------------
111測試
使用GB2312編碼-----------------------------
111測試
使用ISO-8859-1編碼-----------------------------
1112aê?
****************************讀取test1.txt文件 end *****************************
****************************讀取test2.txt文件 start *****************************
使用默認編碼-----------------------------
?##=====Set Dubbo Begin=====
## Dubbo注冊中心地址
使用UTF-8編碼-----------------------------
?##=====Set Dubbo Begin=====
## Dubbo注冊中心地址
使用GBK編碼-----------------------------
锘?##=====Set Dubbo Begin=====
## Dubbo娉ㄥ唽涓績鍦板潃
使用GB2312編碼-----------------------------
锘?##=====Set Dubbo Begin=====
## Dubbo娉ㄥ??涓?蹇??板??
使用ISO-8859-1編碼-----------------------------
???##=====Set Dubbo Begin=====
## Dubbo?3¨?????-?????°??€
****************************讀取test2.txt文件 end *****************************
結果顯而易見,編碼不同出現中文亂碼,這里亂碼的原因是因為 new String()。java在字節轉化為字符時不指定編碼則會使用默認編碼,我的編輯器默認編碼是 UTF-8,所以出現上面的結果。
方式二 : 字符流讀取字符顯示
//通過InputStreamReader讀取字符
String path1 = "C:\\Users\\yanzhichao\\Desktop\\test.txt";
String path2 = "C:\\Users\\yanzhichao\\Desktop\\test2.txt";
InputStreamReader reader1 = null;
InputStreamReader reader2 = null;
try{
System.out.println("以字符為單位讀取文件內容,一次讀多個字節:");
// 一次讀多個字符
char[] tempchars = new char[30];
int charread = 0;
reader1 = new InputStreamReader(new FileInputStream(path1));
System.out.println("使用默認編碼(UTF-8):");
// 讀入多個字符到字符數組中,charread為一次讀取字符數
while ((charread = reader1.read(tempchars)) != -1) {
// 同樣屏蔽掉\r不顯示
if ((charread == tempchars.length)
&& (tempchars[tempchars.length - 1] != '\r')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
System.out.println();
reader2 = new InputStreamReader(new FileInputStream(path1),"GBK");
System.out.println("使用GBK編碼:");
tempchars = new char[30];
charread = 0;
// 讀入多個字符到字符數組中,charread為一次讀取字符數
while ((charread = reader2.read(tempchars)) != -1) {
// 同樣屏蔽掉\r不顯示
if ((charread == tempchars.length)
&& (tempchars[tempchars.length - 1] != '\r')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if(reader1 != null) {
try {
reader1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(reader2 != null) {
try {
reader2.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
代碼只讀取了test.txt,執行結果如下:
以字符為單位讀取文件內容,一次讀多個字節:
使用默認編碼(UTF-8):
111????
使用GBK編碼:
111測試
顯然,和上面是一樣的,需要對應編碼
字節文件一般來說是要對應的工具才能打開的,用記事本打開也看不到什么信息。
這里小編將之前的兩個文件加入到壓縮文件Desktop.rar中,代碼如下:
String path1 = "C:\\Users\\yanzhichao\\Desktop\\test.txt";
String path2 = "C:\\Users\\yanzhichao\\Desktop\\test2.txt";
String zipName = "C:\\Users\\yanzhichao\\Desktop\\Desktop.rar";
String zipName2 = "C:\\Users\\yanzhichao\\Desktop\\Desktop2.rar";
String folderName = "test";
List<String> filePathList = new ArrayList<>();
filePathList.add(path1);
filePathList.add(path2);
InputStream is = null;
InputStream is2 = null;
ZipFile zip = null;
ZipFile zip2 = null;
try {
//方法一
zip = new ZipFile(zipName);
ZipParameters para = null;
File file = null;
for (String fliePath : filePathList) {
file = new File(fliePath);
para = new ZipParameters();
para.setCompressionMethod(Zip4jConstants.COMP_DEFLATE);
para.setFileNameInZip(folderName+ fliePath.substring(fliePath.lastIndexOf(File.separator)));
para.setSourceExternalStream(true);
is = new ByteArrayInputStream(T.FileUtils.readFileToByteArray(file));
zip.addStream(is, para);
}
//方法二
zip2 = new ZipFile(zipName2);
ZipParameters para2 = null;
for (String fliePath : filePathList) {
String content = new String(T.IOUtils.toByteArray(new FileInputStream(fliePath)));
para2 = new ZipParameters();
para2.setCompressionMethod(Zip4jConstants.COMP_DEFLATE);
para2.setFileNameInZip(folderName+ fliePath.substring(fliePath.lastIndexOf(File.separator)));
para2.setSourceExternalStream(true);
is2 = new ByteArrayInputStream(content.getBytes());
zip2.addStream(is2, para2);
}
} catch (ZipException | IOException e) {
e.printStackTrace();
} finally {
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is2 != null) {
try {
is2.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
代碼中使用了zip4j工具類進行壓縮,讀取文件轉換為字節數組使用的是apache的工具類。
執行后的結果是Desktop2.rar中的中文存在亂碼,其他的正常。
如果對壓縮文件進行再壓縮時,第二種方法出來的壓縮文件不會有問題,但是打開里面的壓縮文件會提示損壞。
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習

官方微信

官方抖音

















 京公網安備 11030102010736號
京公網安備 11030102010736號