專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2022-06-01 10:40:34 來源:動力節點 瀏覽1348次
動力節點小編對Java高級特性進行了總結。
在分布式系統要滿足CAP原則,一個提供數據服務的存儲系統無法同時滿足:數據一致性、數據可用性、分區耐受性。
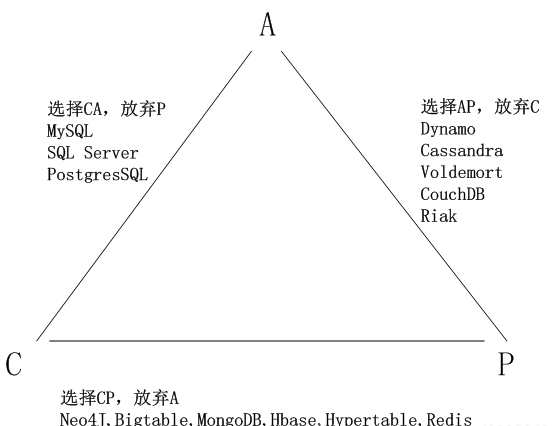
C數據一致性:所有應用程序都能訪問到相同的數據。 A數據可用性:任何時候,任何應用程序都可以讀寫訪問。 P分區耐受性:系統可以跨網絡分區線性伸縮。(通俗來說就是數據的規模可擴展) 在大型網站中通常都是犧牲C,選擇AP。為了可能減小數據不一致帶來的影響,都會采取各種手段保證數據最終一致。
數據強一致:各個副本的數據在物理存儲中總是一致的。
數據用戶一致:數據在物理存儲的各個副本可能是不一致的,但是通過糾錯和校驗機制,會確定一個一致的且正確的數據返回給用戶。
數據最終一致:物理存儲的數據可能不一致,終端用戶訪問也可能不一致,但是一段時間內數據會達成一致。
使一組服務器在一個值上達成一致,所以活躍的特征在于最終每個服務器都可以決定一個值。
通過值的一致能夠實現對同一個數據的請求會讓同一個服務器來處理。
Paxos和Raft都是通過選取master來實現多節點下值的一致性,從而借助一致性hash算法來分配請求。
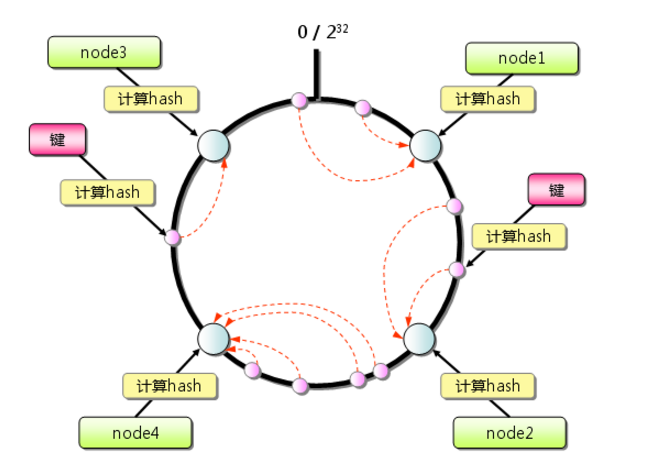
一致性Hash算法 一致性Hash算法可以根據不同的屬性參數(通常是IP和端口號),生成一串不相同的Hash值,并將Hash值轉換成0-2^32-1的整數, 不同范圍的值由不同服務器進行處理。(B-C之間的由B處理)。
Raft算法是在Paxos算法的基礎上的進行優化。 Raft在Paxos的基礎上主要做了兩個方向的優化: 1.將復雜的分布式共識問題拆分成領導選舉、日志復制和安全性三個問題 2.壓縮狀態空間:相對于Paxos施加了更合理的限制,減少了系統狀態過多而產生的不確定因素。
領導選舉(具體以zookeeper舉例) 其基本的特性有:
zookeeper在配置集群時節點數不可小于3
節點只有獲得半數以上的投票才能當選Leader
zookeeper在啟動時會通過廣播機制來把投票結果告訴其他的節點
zookeeper在啟動時首先會給自己投票,然后與其他已啟動的節點進行通信,通過比較id從而判斷是否能獲取其他節點的投票
zookeeper在選舉過程中的角色:領導者、跟隨者、觀察者、競選者
日志復制 在共識算法中,所有服務器節點都會包含一個有限狀態自動機,名為復制狀態機(replicated state machine)。每個節點都維護著一個復制日志(replicated logs)的隊列,復制狀態機會按序輸入并執行該隊列中的請求,執行狀態轉換并輸出結果。可見,如果能保證各個節點中日志的一致性,那么所有節點狀態機的狀態轉換和輸出也就都一致。
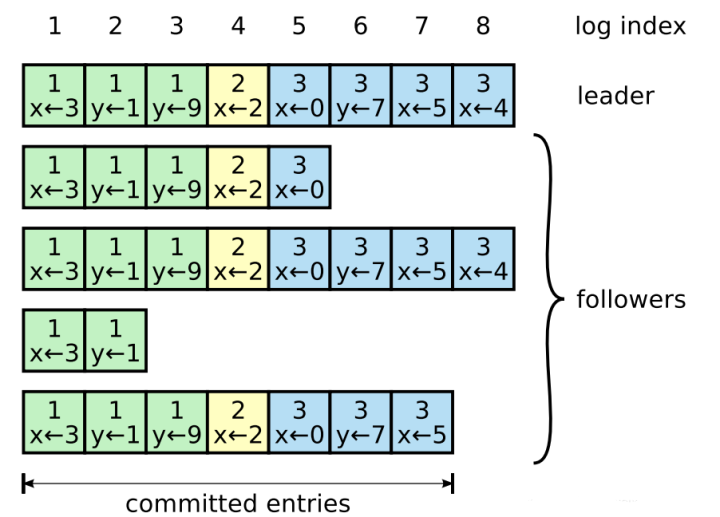
可見,日志由一個個按序排列的entry組成。每個entry內包含有請求的數據,還有該entry產生時的領導任期值。每個節點上的日志隊列用一個數組log[]表示。
領導節點選舉出來后,集群就可以開始處理客戶端請求了。當客戶端發來請求時,領導節點首先將其加入自己的日志隊列,再并行地發送AppendEntries RPC消息給所有跟隨節點。最終實現節點數據的一致性。
安全性 Raft安全保障機制有5種:
選舉安全性:節點要3個以上,避免“腦裂”的方式
領導者只追加:客戶端發出的請求都是插入領導者日志隊列的尾部,沒有修改或刪除的操作。
日志匹配:每條AppendEntries都會包含最新entry之前那個entry的下標與任期值,如果跟隨節點在對應下標找不到對應任期的日志,就會拒絕接受并告知領導節點。(避免追隨者故障,導致數據不一致)
領導者完全性:如果有一條日志在某個任期被提交了,那么它一定會出現在所有任期更大的領導者日志里。(master會優先獲取日志的更新)
狀態機安全性:如果一個節點已經向其復制狀態機應用了一條日志中的請求,那么對于其他節點的同一下標的日志,不能應用不同的請求。(避免master宕機時,重新選舉,導致部分節點數據不一致)
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習




官方微信

官方抖音














 京公網安備 11030102010736號
京公網安備 11030102010736號