專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2022-07-01 10:11:46 來源:動力節點 瀏覽1266次
Lambda 架構是一種數據處理部署模型,組織使用該模型將傳統批處理管道與快速實時流管道相結合以進行數據訪問。它是 IT 和開發組織工具包中的一種常見架構模型,因為面對大量快速生成的數據(通常稱為“大數據”),企業努力變得更加數據驅動和事件驅動。
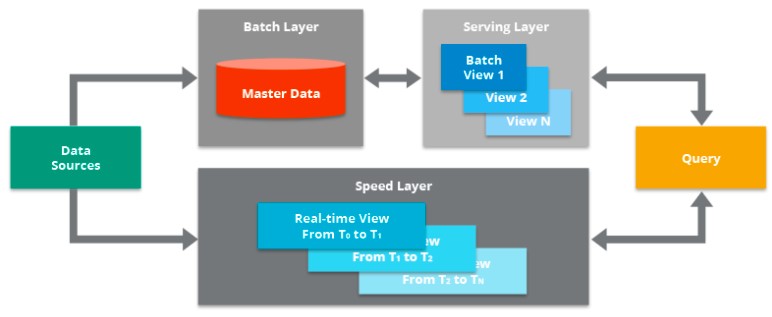
Lambda 架構既包含傳統的批處理數據管道,也包含用于實時數據的快速流傳輸管道,以及用于響應查詢的服務層。
在上圖中,您可以看到 Lambda 架構的主要組件:
數據源。數據可以從各種來源獲得,然后可以包含在 Lambda 架構中進行分析。這個組件通常是像 Apache Kafka 這樣的流式源,它本身不是原始數據源,而是一個可以保存數據的中間存儲,以便為 Lambda 架構的批處理層和速度層提供服務。數據同時傳送到批處理層和速度層,以實現并行索引工作。
批處理層。該組件將所有進入系統的數據保存為批處理視圖,以準備索引。輸入數據保存在一個模型中,該模型看起來像是對記錄系統進行的一系列更改/更新,類似于更改數據捕獲 (CDC)系統的輸出。通常,這只是逗號分隔值 (CSV) 格式的文件。數據被視為不可變且僅追加,以確保所有傳入數據的可信歷史記錄。像 Apache Hadoop 這樣的技術通常被用作一種系統,用于以經濟高效的方式攝取數據以及存儲數據。
服務層。該層對最新的批處理視圖進行增量索引,以使其可供最終用戶查詢。該層還可以重新索引所有數據以修復編碼錯誤或為不同的用例創建不同的索引。服務層的關鍵要求是以極其并行的方式完成處理,以最大限度地減少索引數據集的時間。在運行索引作業時,新到達的數據將排隊等待在下一個索引作業中進行索引。
速度層。該層通過索引最近添加的尚未被服務層完全索引的數據來補充服務層。這包括服務層當前正在索引的數據以及在當前索引作業開始后到達的新數據。由于最新數據添加到系統的時間與最新數據可用于查詢的時間之間存在預期滯后(由于執行批量索引工作需要時間),因此取決于速度層索引最新數據以縮小這一差距。
該層通常利用流處理軟件近乎實時地索引傳入數據,以最大限度地減少獲取可用于查詢的數據的延遲。首次引入 Lambda 架構時,Apache Storm 是部署中使用的領先流處理引擎,但此后其他技術作為該組件的候選技術(如Hazelcast Jet、Apache Flink 和 Apache Spark Streaming)越來越受歡迎。
查詢。該組件負責向服務層和速度層提交最終用戶查詢并合并結果。這為最終用戶提供了對所有數據(包括最近添加的數據)的完整查詢,以提供近乎實時的分析系統。
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習




官方微信

官方抖音














 京公網安備 11030102010736號
京公網安備 11030102010736號