專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2021-08-13 10:17:14 來源:動力節點 瀏覽983次
在本教程中,我們將討論隨著時間的推移建立的一些設計原則和模式,以構建高度并發的應用程序。
但是,值得注意的是,設計并發應用程序是一個廣泛而復雜的主題,因此沒有任何教程可以聲稱對其進行了詳盡的處理。我們將在這里介紹一些經常使用的流行技巧!
在我們繼續之前,讓我們花一些時間了解基礎知識。首先,我們必須澄清我們對所謂的并發程序的理解。如果多個計算同時發生,我們指的是一個程序是并發的。
現在,請注意我們已經提到了同時發生的計算——也就是說,它們同時進行。但是,它們可能會或可能不會同時執行。理解差異很重要,因為同時執行的計算被稱為并行。
(1)如何創建并發模塊?
了解我們如何創建并發模塊很重要。有很多選擇,但我們將在這里重點介紹兩個流行的選擇:
進程:進程是一個正在運行的程序的實例,它與同一臺機器上的其他進程隔離。機器上的每個進程都有自己獨立的時間和空間。因此,通常不可能在進程之間共享內存,它們必須通過傳遞消息進行通信。
線程:另一方面,線程只是進程的一部分。一個程序中可以有多個線程共享相同的內存空間。但是,每個線程都有唯一的堆棧和優先級。線程可以是本地的(由操作系統本地調度)或綠色的(由運行時庫調度)。
(2)并發模塊如何交互?
如果并發模塊不必通信,這是非常理想的,但通常情況并非如此。這產生了兩種并發編程模型:
共享內存:在這個模型中,并發模塊通過在內存中讀寫共享對象來交互。這通常會導致并發計算的交錯,從而導致競爭條件。因此,它可能不確定地導致不正確的狀態。
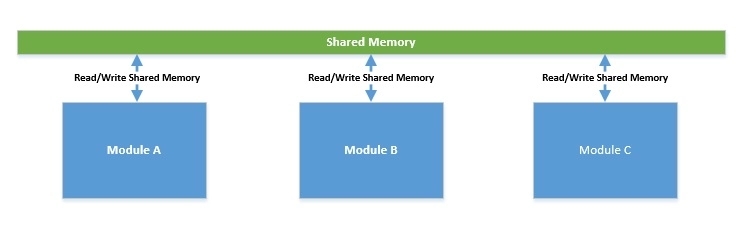
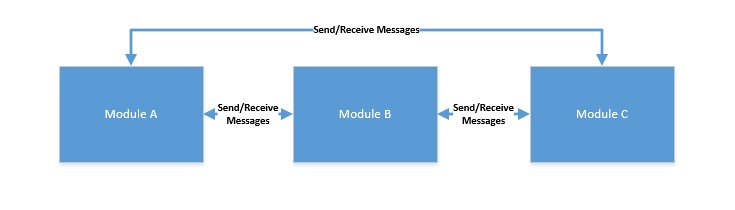
消息傳遞:在此模型中,并發模塊通過通信通道相互傳遞消息來進行交互。在這里,每個模塊按順序處理傳入的消息。由于沒有共享狀態,編程相對容易,但這仍然無法擺脫競爭條件!
(3)并發模塊如何執行?
摩爾定律在處理器的時鐘速度方面遇到瓶頸已經有一段時間了。相反,由于我們必須成長,我們開始將多個處理器集成到同一芯片上,通常稱為多核處理器。但是,聽到超過 32 個內核的處理器的情況并不常見。
現在,我們知道單個內核一次只能執行一個線程或一組指令。但是,進程和線程的數量可以分別為數百和數千。那么,它究竟是如何運作的呢?這是操作系統為我們模擬并發的地方。操作系統通過時間切片來實現這一點——這實際上意味著處理器在線程之間頻繁、不可預測且不確定地切換。
當我們開始討論設計并發應用程序的原則和模式時,首先了解典型問題是什么是明智的。
在很大程度上,我們在并發編程方面的經驗涉及使用具有共享內存的本機線程。因此,我們將重點關注由此產生的一些常見問題:
互斥(Synchronization Primitives):交錯線程需要對共享狀態或內存進行獨占訪問,以保證程序的正確性。共享資源的同步是一種流行的實現互斥的方法。有多種同步原語可供使用——例如,鎖、監視器、信號量或互斥鎖。但是,互斥編程很容易出錯,并且通常會導致性能瓶頸。有幾個與此相關的經過充分討論的問題,例如deadlock 和 livelock。
上下文切換(重量級線程):每個操作系統都有對進程和線程等并發模塊的原生支持,盡管有所不同。如前所述,操作系統提供的一項基本服務是通過時間切片調度線程以在有限數量的處理器上執行。現在,這實際上意味著線程在不同狀態之間頻繁切換。在這個過程中,他們當前的狀態需要被保存和恢復。這是一項直接影響整體吞吐量的耗時活動。
現在,我們了解了并發編程的基礎知識和其中的常見問題,是時候了解一些避免這些問題的常見模式了。我們必須重申,并發編程是一項需要大量經驗的艱巨任務。因此,遵循一些既定的模式可以使任務更容易。
(1)基于 Actor 的并發
我們將討論的關于并發編程的第一個設計稱為 Actor 模型。這是一個并發計算的數學模型,基本上把一切都當作一個參與者。參與者可以相互傳遞消息,并且可以根據消息做出本地決策。這是由 Carl Hewitt 首次提出的,并啟發了許多編程語言。
Scala 并發編程的主要結構是actor。Actor 是 Scala 中的普通對象,我們可以通過實例化Actor類來創建它們。此外,Scala Actors 庫提供了許多有用的 actor 操作:
class myActor extends Actor {
def act() {
while(true) {
receive {
// Perform some action
}
}
}
}
在上面的示例中,在無限循環中調用receive方法會掛起 actor,直到消息到達。消息到達后,從參與者的郵箱中刪除,并采取必要的行動。
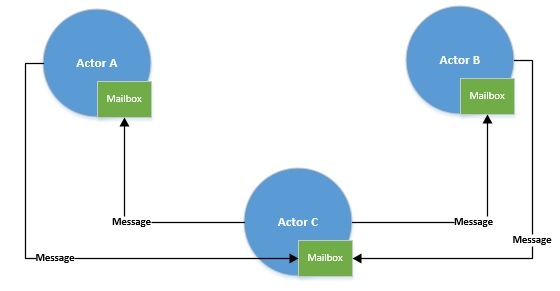
參與者模型消除了并發編程的一個基本問題——共享內存。Actors 通過消息進行通信,每個 Actor 依次處理來自其專用郵箱的消息。但是,我們通過線程池執行actor。我們已經看到原生線程可能是重量級的,因此數量有限。
當然,這里還有其他模式可以幫助我們——我們稍后會介紹這些!
(2)基于事件的并發
基于事件的設計明確解決了原生線程的生成和操作成本高的問題。基于事件的設計之一是事件循環。事件循環與事件提供程序和一組事件處理程序一起工作。在此設置中,事件循環阻塞事件提供者,并在到達時將事件分派給事件處理程序。
基本上,事件循環只不過是一個事件調度器!事件循環本身可以僅在單個本機線程上運行。那么,事件循環中到底發生了什么?讓我們以一個非常簡單的事件循環的偽代碼為例:
while(true) {
events = getEvents();
for(e in events)
processEvent(e);
}
基本上,我們的事件循環所做的就是不斷尋找事件,并在找到事件時處理它們。該方法非常簡單,但它獲得了事件驅動設計的好處。
使用這種設計構建并發應用程序可以更好地控制應用程序。此外,它還消除了多線程應用程序的一些典型問題,例如死鎖。
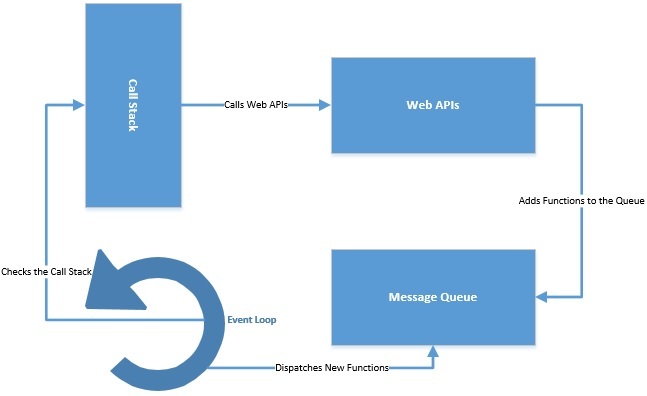
JavaScript 實現事件循環以提供異步編程。它維護一個調用堆棧來跟蹤要執行的所有函數。它還維護一個事件隊列,用于發送新函數進行處理。事件循環不斷檢查調用堆棧并從事件隊列中添加新函數。所有異步調用都被分派到 Web API,通常由瀏覽器提供。
事件循環本身可以在單個線程上運行,但 Web API 提供單獨的線程。
(3)非阻塞算法
在非阻塞算法中,一個線程的掛起不會導致其他線程的掛起。我們已經看到,我們的應用程序中只能有有限數量的本機線程。現在,阻塞線程的算法顯然會顯著降低吞吐量 并阻止我們構建高度并發的應用程序。
非阻塞算法總是利用底層硬件提供的比較和交換原子原語。這意味著硬件會將內存位置的內容與給定值進行比較,并且僅當它們相同時才會將值更新為新的給定值。這可能看起來很簡單,但它有效地為我們提供了一個原子操作,否則將需要同步。
這意味著我們必須編寫使用這種原子操作的新數據結構和庫。這為我們提供了大量的多種語言的無等待和無鎖實現。Java 有幾個非阻塞數據結構,如AtomicBoolean、AtomicInteger、AtomicLong和AtomicReference。
考慮一個應用程序,其中多個線程試圖訪問相同的代碼:
boolean open = false;
if(!open) {
// Do Something
open=false;
}
顯然,上面的代碼不是線程安全的,它在多線程環境中的行為是不可預測的。我們在這里的選擇是將這段代碼與鎖同步或使用原子操作:
AtomicBoolean open = new AtomicBoolean(false);
if(open.compareAndSet(false, true) {
// Do Something
}
正如我們所見,使用像AtomicBoolean這樣的非阻塞數據結構可以幫助我們編寫線程安全的代碼,而不會沉迷于鎖的缺點!
我們已經看到有多種方法可以構建并發模塊。雖然編程語言確實有所作為,但主要是底層操作系統如何支持這一概念。然而,由于本機線程支持的基于線程的并發在可擴展性方面遇到了新的障礙,我們總是需要新的選擇。
實施我們在上一節中討論的一些設計實踐確實證明是有效的。但是,我們必須記住,它確實使編程變得復雜。我們真正需要的是能夠提供基于線程并發的強大功能而又不會帶來不良影響的東西。
我們可用的一種解決方案是綠色線程。綠色線程是由運行時庫調度的線程,而不是由底層操作系統本地調度的線程。雖然這并不能解決基于線程的并發中的所有問題,但在某些情況下它確實可以為我們提供更好的性能。
現在,除非我們選擇使用的編程語言支持它,否則使用綠色線程并非易事。并非每種編程語言都有這種內置支持。此外,我們松散地稱為綠色線程的東西可以通過不同的編程語言以非常獨特的方式實現。讓我們看看其中一些可供我們使用的選項。
(1)Go 中的 Goroutine
Go 編程語言中的Goroutine是輕量級線程。它們提供可以與其他函數或方法同時運行的函數或方法。Goroutines非常便宜,因為它們在堆棧大小中僅占用幾千字節,從.
最重要的是,goroutines 與較少數量的本地線程復用。此外,goroutine 使用通道相互通信,從而避免訪問共享內存。我們幾乎得到了我們需要的一切,然后你猜怎么著——什么都不做!
(2)Erlang 中的進程
在Erlang 中,每個執行線程都稱為一個進程。但是,這與我們目前討論的過程不太一樣!Erlang 進程是輕量級的,內存占用小,創建和處理速度快,調度開銷低。
在幕后,Erlang 進程只不過是運行時處理調度的函數。此外,Erlang 進程不共享任何數據,它們通過消息傳遞相互通信。這就是我們首先稱這些“過程”的原因!
(3)Java 中的 Fibers(提案)
Java 并發的故事一直在不斷演變。Java 確實支持綠色線程,至少對于 Solaris 操作系統,一開始是這樣。但是,由于超出本教程范圍的障礙,這已停止。
從那時起,Java 中的并發就是關于本機線程以及如何巧妙地使用它們!但出于顯而易見的原因,我們可能很快就會在 Java 中擁有一個新的并發抽象,稱為纖程。Project Loom提議將 continuation 與Fiber一起引入,這可能會改變我們在 Java 中編寫并發應用程序的方式!
這只是對不同編程語言中可用內容的先睹為快。其他編程語言嘗試處理并發性的方式要有趣得多。
此外,值得注意的是,在設計高并發應用程序時,上一節中討論的設計模式的組合以及對類似綠色線程的抽象的編程語言支持可能非常強大。
現實世界的應用程序通常有多個組件通過網絡相互交互。我們通常通過互聯網訪問它,它由多種服務組成,如代理服務、網關、Web 服務、數據庫、目錄服務和文件系統。
這種情況下如何保證高并發?讓我們探索其中的一些層以及構建高度并發應用程序的選項。
正如我們在上一節中看到的,構建高并發應用程序的關鍵是使用那里討論的一些設計概念。我們需要為工作選擇合適的軟件——那些已經包含了其中一些實踐的軟件。
(1)網絡層
Web 通常是用戶請求到達的第一層,這里不可避免地需要提供高并發性。讓我們看看有哪些選項:
Node(也稱為 NodeJS 或 Node.js)是一個基于 Chrome 的 V8 JavaScript 引擎構建的開源、跨平臺 JavaScript 運行時。Node 在處理異步 I/O 操作方面工作得很好。Node 做得這么好的原因是因為它在單個線程上實現了一個事件循環。事件循環在回調的幫助下異步處理所有阻塞操作,如 I/O。
nginx是一個開源 Web 服務器,我們通常將其用作反向代理以及其他用途。nginx 提供高并發的原因是它使用異步的、事件驅動的方法。nginx 在單個線程中與主進程一起運行。主進程維護執行實際處理的工作進程。因此,工作進程并發地處理每個請求。
(2)應用層
在設計應用程序時,有幾個工具可以幫助我們構建高并發。讓我們來看看我們可以使用的一些庫和框架:
Akka是一個用 Scala 編寫的工具包,用于在 JVM 上構建高并發和分布式應用程序。Akka 處理并發的方法基于我們之前討論過的 actor 模型。Akka 在參與者和底層系統之間創建了一個層。該框架處理創建和調度線程、接收和分派消息的復雜性。
Project Reactor 是一個反應庫,用于在 JVM 上構建非阻塞應用程序。它基于 Reactive Streams 規范,專注于高效的消息傳遞和需求管理(背壓)。Reactor 操作符和調度器可以維持消息的高吞吐率。幾個流行的框架提供了 reactor 實現,包括 Spring WebFlux 和 RSocket。
Netty是一個異步的、事件驅動的網絡應用程序框架。我們可以使用 Netty 來開發高并發協議服務器和客戶端。Netty 利用NIO,它是 Java API 的集合,通過緩沖區和通道提供異步數據傳輸。它為我們提供了幾個優勢,例如更好的吞吐量、更低的延遲、更少的資源消耗以及最小化不必要的內存復制。
(3)數據層
最后,沒有數據的應用程序是不完整的,數據來自持久存儲。當我們討論與數據庫相關的高并發時,大部分焦點仍然放在 NoSQL 系列上。這主要是由于 NoSQL 數據庫可以提供線性可擴展性,但在關系變體中很難實現。讓我們來看看數據層的兩個流行工具:
Cassandra是一種免費的開源 NoSQL 分布式數據庫,可在商品硬件上提供高可用性、高可擴展性和容錯性。但是,Cassandra 不提供跨多個表的 ACID 事務。因此,如果我們的應用程序不需要強一致性和事務,我們可以從 Cassandra 的低延遲操作中受益。
Kafka是一個分布式流媒體平臺。Kafka 將記錄流存儲在稱為主題的類別中。它可以為記錄的生產者和消費者提供線性水平可擴展性,同時提供高可靠性和持久性。分區、副本和代理是它提供大規模分布式并發的一些基本概念。
(4)緩存層
好吧,現代世界中沒有任何以高并發為目標的 Web 應用程序能夠承受每次訪問數據庫的代價。這讓我們選擇一個緩存——最好是一個可以支持我們高并發應用程序的內存緩存:
Hazelcast 是一個分布式,云友好的,內存中的對象存儲和計算引擎,支持多種數據結構,如地圖,設置,列表,多重映射, RingBuffer和HyperLogLog。它具有內置復制并提供高可用性和自動分區。
Redis 是一種內存數據結構存儲,我們主要用作緩存。它提供了一個具有可選持久性的內存鍵值數據庫。支持的數據結構包括字符串、散列、列表和集合。Redis 具有內置復制并提供高可用性和自動分區。如果我們不需要持久性,Redis可以為我們提供一個功能豐富、網絡化、性能卓越的內存緩存。
當然,在我們追求構建高度并發的應用程序的過程中,我們幾乎沒有觸及可用內容的皮毛。重要的是要注意,除了可用的軟件之外,我們的需求還應該指導我們創建合適的設計。其中一些選項可能合適,而其他選項可能不合適。
而且,我們不要忘記,還有更多可能更適合我們要求的選項。
以上就是動力節點小編介紹的"高并發應用的設計原則和模式",希望對大家有幫助,想了解更多可查看Java在線學習。動力節點在線學習教程,針對沒有任何Java基礎的讀者學習,讓你從入門到精通,主要介紹了一些Java基礎的核心知識,讓同學們更好更方便的學習和了解Java編程,感興趣的同學可以關注一下。
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習




官方微信

官方抖音














 京公網安備 11030102010736號
京公網安備 11030102010736號