專注Java教育14年
全國咨詢/投訴熱線:400-8080-105
更新時間:2021-06-17 11:03:43 來源:動力節點 瀏覽1096次
RabbitMQ這款消息隊列中間件產品本身是基于Erlang編寫,Erlang語言天生具備分布式特性(通過同步Erlang集群各節點的magic cookie來實現)。因此,RabbitMQ天然支持Clustering。這使得RabbitMQ本身不需要像ActiveMQ、Kafka那樣通過ZooKeeper分別來實現HA方案和保存集群的元數據。集群是保證可靠性的一種方式,同時可以通過水平擴展以達到增加消息吞吐量能力的目的。 下面先來看下RabbitMQ集群的整體方案:
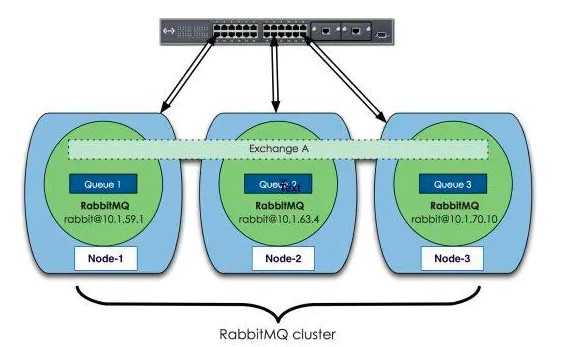
上面圖中采用三個節點組成了一個RabbitMQ的集群,Exchange A(交換器,對于RabbitMQ基礎概念不太明白的童鞋可以看下基礎概念)的元數據信息在所有節點上是一致的,而Queue(存放消息的隊列)的完整數據則只會存在于它所創建的那個節點上。,其他節點只知道這個queue的metadata信息和一個指向queue的owner node的指針。
(1)RabbitMQ集群元數據的同步
RabbitMQ集群會始終同步四種類型的內部元數據(類似索引):
a.隊列元數據:隊列名稱和它的屬性;
b.交換器元數據:交換器名稱、類型和屬性;
c.綁定元數據:一張簡單的表格展示了如何將消息路由到隊列;
d.vhost元數據:為vhost內的隊列、交換器和綁定提供命名空間和安全屬性;
因此,當用戶訪問其中任何一個RabbitMQ節點時,通過rabbitmqctl查詢到的queue/user/exchange/vhost等信息都是相同的。
(2)為何RabbitMQ集群僅采用元數據同步的方式
我想肯定有不少同學會問,想要實現HA方案,那將RabbitMQ集群中的所有Queue的完整數據在所有節點上都保存一份不就可以了么?(可以類似MySQL的主主模式嘛)這樣子,任何一個節點出現故障或者宕機不可用時,那么使用者的客戶端只要能連接至其他節點能夠照常完成消息的發布和訂閱嘛。
我想RabbitMQ的作者這么設計主要還是基于集群本身的性能和存儲空間上來考慮。第一,存儲空間,如果每個集群節點都擁有所有Queue的完全數據拷貝,那么每個節點的存儲空間會非常大,集群的消息積壓能力會非常弱(無法通過集群節點的擴容提高消息積壓能力);第二,性能,消息的發布者需要將消息復制到每一個集群節點,對于持久化消息,網絡和磁盤同步復制的開銷都會明顯增加。
(3)RabbitMQ集群發送/訂閱消息的基本原理
RabbitMQ集群的工作原理圖如下:
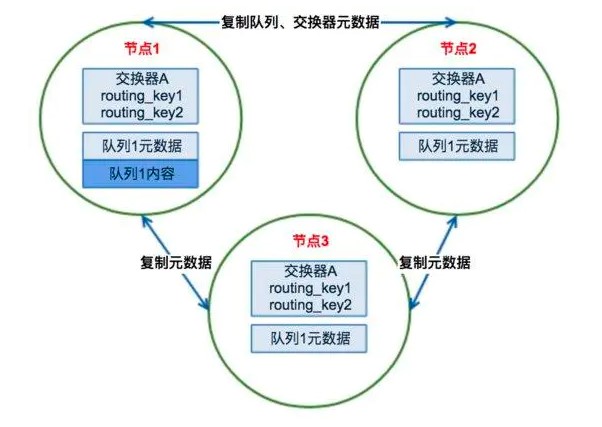
場景1.客戶端直接連接隊列所在節點
如果有一個消息生產者或者消息消費者通過amqp-client的客戶端連接至節點1進行消息的發布或者訂閱,那么此時的集群中的消息收發只與節點1相關,這個沒有任何問題;如果客戶端相連的是節點2或者節點3(隊列1數據不在該節點上),那么情況又會是怎么樣呢?
場景2.客戶端連接的是非隊列數據所在節點
如果消息生產者所連接的是節點2或者節點3,此時隊列1的完整數據不在該兩個節點上,那么在發送消息過程中這兩個節點主要起了一個路由轉發作用,根據這兩個節點上的元數據(也就是上文提到的:指向queue的owner node的指針)轉發至節點1上,最終發送的消息還是會存儲至節點1的隊列1上。
同樣,如果消息消費者所連接的節點2或者節點3,那這兩個節點也會作為路由節點起到轉發作用,將會從節點1的隊列1中拉取消息進行消費。
(1)搭建RabbitMQ集群所需要安裝的組件
在搭建RabbitMQ集群之前有必要在每臺虛擬機上安裝如下的組件包,分別如下:
a.Jdk 1.8
b.Erlang運行時環境,這里用的是otp_src_19.3.tar.gz (200MB+)
c.RabbitMq的Server組件,這里用的rabbitmq-server-generic-unix-3.6.10.tar.gz
關于如何安裝上述三個組件的具體步驟,已經有不少博文對此進行了非常詳細的描述,那么本文就不再贅述了。有需要的同學可以具體參考這些步驟來完成安裝。
(2)搭建10節點組成的RabbitMQ集群
該節中主要展示的是集群搭建,需要確保每臺機器上正確安裝了上述三種組件,并且每臺虛擬機上的RabbitMQ的實例能夠正常啟動起來。
a.編輯每臺RabbitMQ的cookie文件,以確保各個節點的cookie文件使用的是同一個值,可以scp其中一臺機器上的cookie至其他各個節點,cookie的默認路徑為/var/lib/rabbitmq/.erlang.cookie或者$HOME/.erlang.cookie,節點之間通過cookie確定相互是否可通信。
b.配置各節點的hosts文件( vim /etc/hosts)
xxx.xxx.xxx.xxx rmq-broker-test-1
xxx.xxx.xxx.xxx rmq-broker-test-2
xxx.xxx.xxx.xxx rmq-broker-test-3
......
xxx.xxx.xxx.xxx rmq-broker-test-10
c.逐個節點啟動RabbitMQ服務
rabbitmq-server -detached
d.查看各個節點和集群的工作運行狀態
rabbitmqctl status, rabbitmqctl cluster_status
e.以rmq-broker-test-1為主節點,在rmq-broker-test-2上:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@rmq-broker-test-2
rabbitmqctl start_app
在其余的節點上的操作步驟與rmq-broker-test-2虛擬機上的一樣。
d.在RabbitMQ集群中的節點只有兩種類型:內存節點/磁盤節點,單節點系統只運行磁盤類型的節點。而在集群中,可以選擇配置部分節點為內存節點。
內存節點將所有的隊列,交換器,綁定關系,用戶,權限,和vhost的元數據信息保存在內存中。而磁盤節點將這些信息保存在磁盤中,但是內存節點的性能更高,為了保證集群的高可用性,必須保證集群中有兩個以上的磁盤節點,來保證當有一個磁盤節點崩潰了,集群還能對外提供訪問服務。在上面的操作中,可以通過如下的方式,設置新加入的節點為內存節點還是磁盤節點:
#加入時候設置節點為內存節點(默認加入的為磁盤節點)
[root@mq-testvm1 ~]# rabbitmqctl join_cluster rabbit@rmq-broker-test-1 --ram
#也通過下面方式修改的節點的類型
[root@mq-testvm1 ~]# rabbitmqctl changeclusternode_type disc | ram
e.最后可以通過“rabbitmqctl cluster_status”的方式來查看集群的狀態,上面搭建的10個節點的RabbitMQ集群狀態(3個節點為磁盤即誒但,7個節點為內存節點)如下:
Cluster status of node 'rabbit@rmq-broker-test-1'
[{nodes,[{disc,['rabbit@rmq-broker-test-1','rabbit@rmq-broker-test-2',
'rabbit@rmq-broker-test-3']},
{ram,['rabbit@rmq-broker-test-9','rabbit@rmq-broker-test-8',
'rabbit@rmq-broker-test-7','rabbit@rmq-broker-test-6',
'rabbit@rmq-broker-test-5','rabbit@rmq-broker-test-4',
'rabbit@rmq-broker-test-10']}]},
{running_nodes,['rabbit@rmq-broker-test-10','rabbit@rmq-broker-test-5',
'rabbit@rmq-broker-test-9','rabbit@rmq-broker-test-2',
'rabbit@rmq-broker-test-8','rabbit@rmq-broker-test-7',
'rabbit@rmq-broker-test-6','rabbit@rmq-broker-test-3',
'rabbit@rmq-broker-test-4','rabbit@rmq-broker-test-1']},
{cluster_name,<<"rabbit@mq-testvm1">>},
{partitions,[]},
{alarms,[{'rabbit@rmq-broker-test-10',[]},
{'rabbit@rmq-broker-test-5',[]},
{'rabbit@rmq-broker-test-9',[]},
{'rabbit@rmq-broker-test-2',[]},
{'rabbit@rmq-broker-test-8',[]},
{'rabbit@rmq-broker-test-7',[]},
{'rabbit@rmq-broker-test-6',[]},
{'rabbit@rmq-broker-test-3',[]},
{'rabbit@rmq-broker-test-4',[]},
{'rabbit@rmq-broker-test-1',[]}]}]
(3)配置HAProxy
HAProxy提供高可用性、負載均衡以及基于TCP和HTTP應用的代理,支持虛擬主機,它是免費、快速并且可靠的一種解決方案。根據官方數據,其最高極限支持10G的并發。HAProxy支持從4層至7層的網絡交換,即覆蓋所有的TCP協議。就是說,Haproxy 甚至還支持 Mysql 的均衡負載。為了實現RabbitMQ集群的軟負載均衡,這里可以選擇HAProxy。
關于HAProxy如何安裝的文章之前也有很多同學寫過,這里就不再贅述了,有需要的同學可以參考下網上的做法。這里主要說下安裝完HAProxy組件后的具體配置。
HAProxy使用單一配置文件來定義所有屬性,包括從前端IP到后端服務器。下面展示了用于7個RabbitMQ節點組成集群的負載均衡配置(另外3個磁盤節點用于保存集群的配置和元數據,不做負載)。同時,HAProxy運行在另外一臺機器上。HAProxy的具體配置如下:
#全局配置
global
#日志輸出配置,所有日志都記錄在本機,通過local0輸出
log 127.0.0.1 local0 info
#最大連接數
maxconn 4096
#改變當前的工作目錄
chroot /apps/svr/haproxy
#以指定的UID運行haproxy進程
uid 99
#以指定的GID運行haproxy進程
gid 99
#以守護進程方式運行haproxy #debug #quiet
daemon
#debug
#當前進程pid文件
pidfile /apps/svr/haproxy/haproxy.pid
#默認配置
defaults
#應用全局的日志配置
log global
#默認的模式mode{tcp|http|health}
#tcp是4層,http是7層,health只返回OK
mode tcp
#日志類別tcplog
option tcplog
#不記錄健康檢查日志信息
option dontlognull
#3次失敗則認為服務不可用
retries 3
#每個進程可用的最大連接數
maxconn 2000
#連接超時
timeout connect 5s
#客戶端超時
timeout client 120s
#服務端超時
timeout server 120s
maxconn 2000
#連接超時
timeout connect 5s
#客戶端超時
timeout client 120s
#服務端超時
timeout server 120s
#綁定配置
listen rabbitmq_cluster
bind 0.0.0.0:5672
#配置TCP模式
mode tcp
#加權輪詢
balance roundrobin
#RabbitMQ集群節點配置,其中ip1~ip7為RabbitMQ集群節點ip地址
server rmq_node1 ip1:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node2 ip2:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node3 ip3:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node4 ip4:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node5 ip5:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node6 ip6:5672 check inter 5000 rise 2 fall 3 weight 1
server rmq_node7 ip7:5672 check inter 5000 rise 2 fall 3 weight 1
#haproxy監控頁面地址
listen monitor
bind 0.0.0.0:8100
mode http
option httplog
stats enable
stats uri /stats
stats refresh 5s
在上面的配置中“listen rabbitmq_cluster bind 0.0.0.0:5671”這里定義了客戶端連接IP地址和端口號。這里配置的負載均衡算法是roundrobin—加權輪詢。與配置RabbitMQ集群負載均衡最為相關的是“ server rmq_node1 ip1:5672 check inter 5000 rise 2 fall 3 weight 1”這種,它標識并且定義了后端RabbitMQ的服務。主要含義如下:
(a)“server ”部分:定義HAProxy內RabbitMQ服務的標識;
(b)“ip1:5672”部分:標識了后端RabbitMQ的服務地址;
(c)“check inter ”部分:表示每隔多少毫秒檢查RabbitMQ服務是否可用;
(d)“rise ”部分:表示RabbitMQ服務在發生故障之后,需要多少次健康檢查才能被再次確認可用;
(e)“fall ”部分:表示需要經歷多少次失敗的健康檢查之后,HAProxy才會停止使用此RabbitMQ服務。
#啟用HAProxy服務
[root@mq-testvm12 conf]# haproxy -f haproxy.cfg
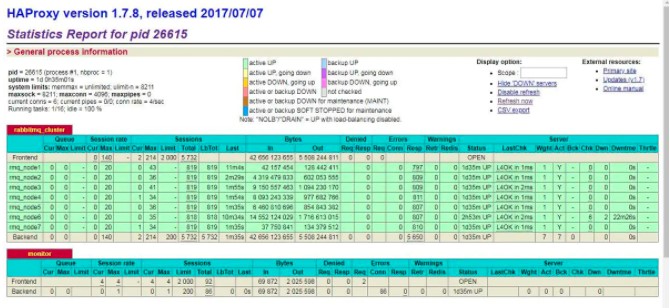
啟動后,即可看到如下的HAproxy的界面圖:
(4)RabbitMQ的集群架構設計圖
經過上面的RabbitMQ10個節點集群搭建和HAProxy軟彈性負載均衡配置后即可組建一個中小規模的RabbitMQ集群了,然而為了能夠在實際的生產環境使用還需要根據實際的業務需求對集群中的各個實例進行一些性能參數指標的監控,從性能、吞吐量和消息堆積能力等角度考慮,可以選擇Kafka來作為RabbitMQ集群的監控隊列使用。因此,這里先給出了一個中小規模RabbitMQ集群架構設計圖:
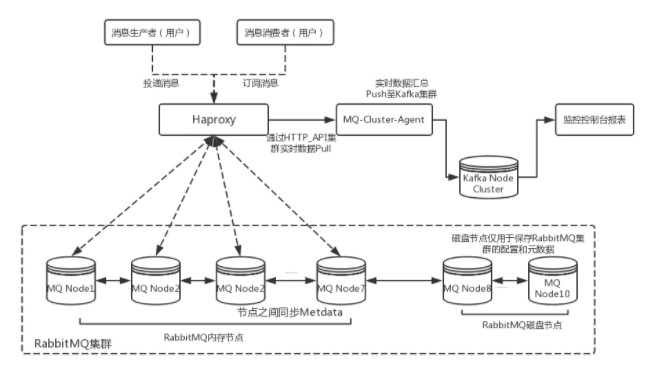
對于消息的生產和消費者可以通過HAProxy的軟負載將請求分發至RabbitMQ集群中的Node1~Node7節點,其中Node8~Node10的三個節點作為磁盤節點保存集群元數據和配置信息。鑒于篇幅原因這里就不在對監控部分進行詳細的描述的,會在后續篇幅中對如何使用RabbitMQ的HTTP API接口進行監控數據統計進行詳細闡述。
本文主要詳細介紹了RabbitMQ集群的工作原理和如何搭建一個具備負載均衡能力的中小規模RabbitMQ集群的方法,并最后給出了RabbitMQ集群的架構設計圖。限于筆者的才疏學淺,對本文內容可能還有理解不到位的地方,如有闡述不合理之處還望留言一起探討。
以上就是動力節點小編介紹的"RabbitMQ集群原理",希望對大家有幫助,如有疑問,請在線咨詢,有專業老師隨時為您服務。
 Java實驗班
Java實驗班
0基礎 0學費 15天面授
 Java就業班
Java就業班
有基礎 直達就業
 Java夜校直播班
Java夜校直播班
業余時間 高薪轉行
 Java在職加薪班
Java在職加薪班
工作1~3年,加薪神器
 Java架構師班
Java架構師班
工作3~5年,晉升架構
提交申請后,顧問老師會電話與您溝通安排學習




官方微信

官方抖音














 京公網安備 11030102010736號
京公網安備 11030102010736號